1. 统计学常识
了解常用的的一些统计学知识,对您解读数据更好实现数据驱动非常有帮助。本节将会对A/B测试中使用到的一些统计学概念进行简单的说明,详细的统计学知识这里并不会涉及。
1.1. 常用的统计学概念
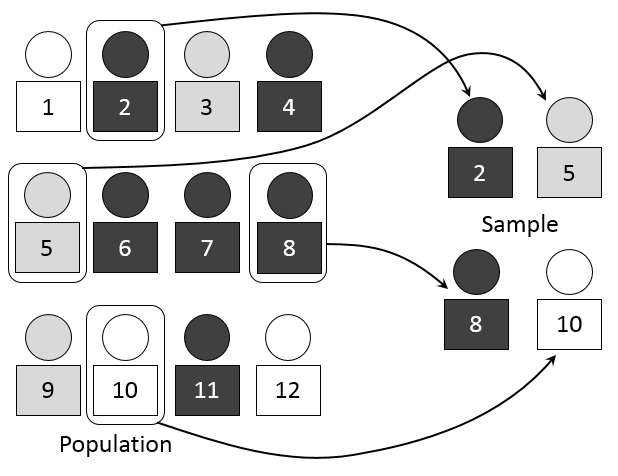
总体
是指统计学中是指由许多有某种共同性质的事物组成的集合,会在此集中选出样本进行统计推断,选取样本的方式可能会用乱数或是其他抽样方式。如要针对所有乌鸦的共有特性进行研究,总体是目前存在、以前曾经存在或是未来可能存在的所有乌鸦,此情形下,因为时间的限制、地域可取得性的限制、以及研究者的有限资源等,不可能观测总体中的每一个,因此研究者会从总体中产生样本,再由样本的特性去了解总体的特性。维基百科
互联网产品中总体数据可以认为所有使用过产品的用户,即截止目前所有注册过App或者访问过网站的用户。由于流失用户的存在,AB测试中实际上不可能取到严格意义上的总体,所以狭义上AB测试期间所有打开App的用户可以认为是总体数据。
抽样
在统计学中,抽样(Sampling)是一种推论统计方法,它是指从目标总体中抽取一部分个体作为样本,通过观察样本的某一或某些属性,依据所获得的数据对总体的数量特征得出具有一定可靠性的估计判断,从而达到对总体的认识。
抽样调查,访谈以及AB测试都属于抽样,都是希望通过抽样对用户总体进行评估。同时,实际工作中由于技术或者成本原因,直接对总体进行调查是不现实或者不经济的。例如:某一个重大App改版,全量上线之后发现效果不好,损失已经很难挽回了。
参数
统计学中,描述总体特征的概括性数字度量,它是研究者想要了解的总体的某种特征值。典型如:均值,标准差,四分值,最大值。
参数估计
当在研究中从样本获得一组数据后,如何通过这组信息对总体特征进行估计,也就是如何从局部结果推论总体的情况,称为总体参数估计。从估计形式看,区分为点估计与区间估计。AB测试中的置信区间就是典型的区间估计。这两个概念是AB测试中的核心概念,本节将会对这两个概念做详细说明:
点估计
是用样本统计量来估计总体参数,因为样本统计量为数轴上某一点值,估计的结果也以一个点的数值表示,所以称为点估计。 假设某一个AB测试中,产品希望提升用户的下单转化率。抽取10,000个用户展现新的商品详情页作为版本1,同时取10,000个用户不做任何变动作为版本0
- 实验数据为版本A中共有6,000下单,版本0有5,000下单,数据解读如下:
* 版本1的下单转化率为60%,据此预估如果全量用户都上线版本1,下单转化率为60%。 * 版本0的下单转化率为50%,据此预估如果全量用户不做变动,下单转化率为50% * 可以得出结论:版本1的下单转化率提升20%
本次实验中,因为没有全量数据,所以将60%,50%,20%作为全量数据的预估。直观上来看,这些数据
必然总体数据存在一定的差异,区间估计就是对这个误差范围进行预估,所以如果业务方仅仅根据20%
这一个数据得出版本1是好的,显然是不够的。
区间估计
通过从总体中抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,以作为总体的分布参数(或参数的函数)的真值所在范围的估计。从定义上看,区间估计需要在一定的准确度的基础上,计算点估计量的误差范围。具体思路是将这个问题转化为概率问题,接下来对这个问题进行简单解读:
- 假设一个抽样得出样本均值为x_bar,如果进行多次抽样可以认为x_bar的分布服从概率分布,根据大树定律这个分布为正态分布;
- 上述问题可以转化为如下概率问题,确定一个变量范围并且保证这些值发生的概率小于某一个特定的值。
这个问题中特定的值也既我们经常所说的置信度(一般设为95%),这个问题中的变量范围就是我们需
计算的置信区间。同时概率中一般认为95%范围以外的数据为小概率事件,同时一般认为小概览事件在
一次实验中不会发生。所以如果置信区间的下限大于零,可以认为这个实验的效果确实有所提升
置信区间
置信区间是指由样本统计量所构造的总体参数的估计区间,属于区间估计的一种。在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的是被测量参数的测量值的可信程度,即前面所要求的“一个概率”。理论依据如下百度百科:
- 对于一组给定的样本数据,其平均值为μ,标准偏差为σ,则其整体数据的平均值的100(1-α)%。置信区间为(μ-Ζα/2σ , μ+Ζα/2σ) ,其中α为非置信水平在正态分布内的覆盖面积 ,Ζα/2即为对应的标准分数。
HubbleData中的置信区间是对不同版本之间差值的区间估计,置信度为百分之九十五。可以理解为不同版本
的变化值存在的差值为X%,HubbleData的区间估计计算的结果为百分九十五的情况下X存在[X1%,X2%]