1. 编程实验
本节将会介绍完整的实验创建流程,包括填写实验信息,确定实验变量,接入SDK以及使用实验变量。
路径:实验管理--新增实验
1.1. 基本流程
本节将会以一个实例来对整个实验流程进行描述,请按照以下环节进行实验的创建与控制。

1.1.1. 基本信息
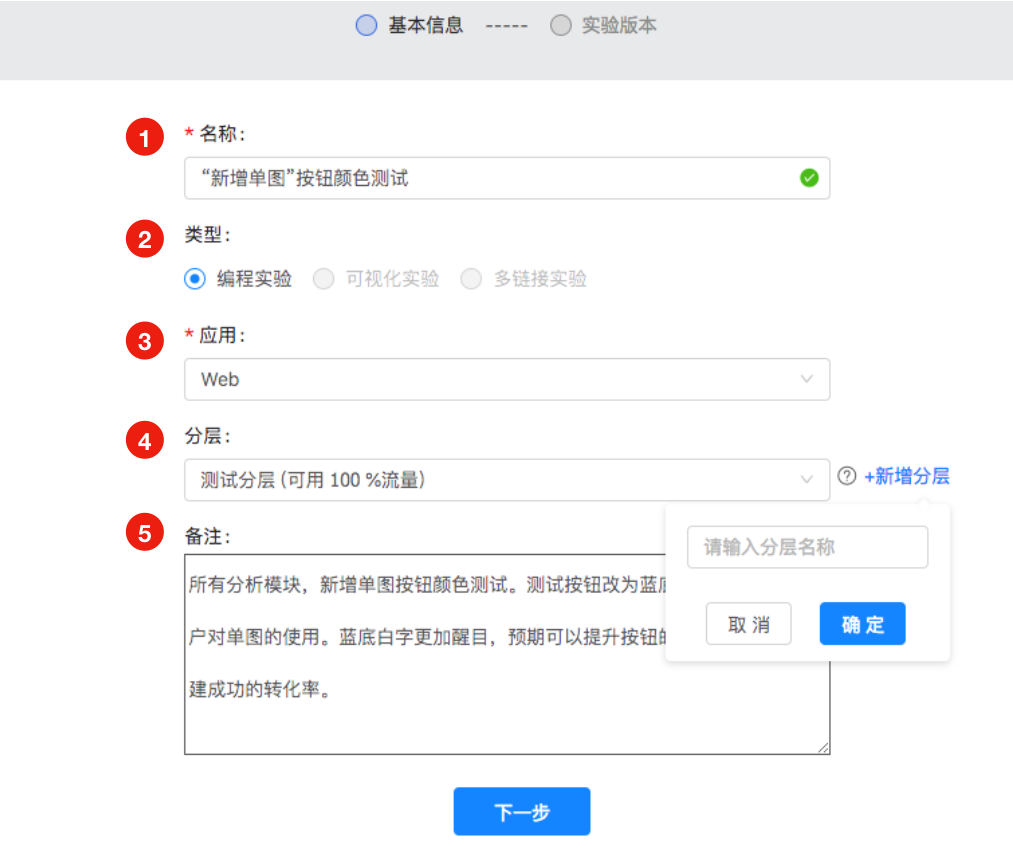
- 填入实验名称,为了方便大家理解,推荐实验名称跟实验内容保持一致。例如针对注册按钮的设计不同的实验方案时,最好以“注册按钮颜色测试”作为名称。
- 实验类型选择,HubbleData支持三种实验类型选择,分别是编程实验,可视化实验以及多链接实验。本节将主要介绍编程实验的创建流程以及注意事项。
- 选择实验运行的应用平台,应用的创建以及管理请在HubbleData的分析平台上管理。
实验多个分层可以认为流量的多次复用:
- 同一分层的实验流量相加为百分之百,同一时段用户仅会参与指定分层的一个实验。
不同分层的实验流量互不干扰,同一时段用户可能会参与两个或多个实验。(实验处于不同分层)
如果想要尽可能放大实验流量,可以选择在新建一个实验分层。请在实验之前确认, 不同分层的实验之间不会互相影响。
- 请认真填写实验备注信息,实验备注信息包括以下内容:
- 实验内容,新设计的逻辑以及实验逻辑跟原有方案的区别,新的特点等等;
- 实验目的以及预期,新的设计方案希望实现的效果以及优化指标。
1.1.2. 实验版本
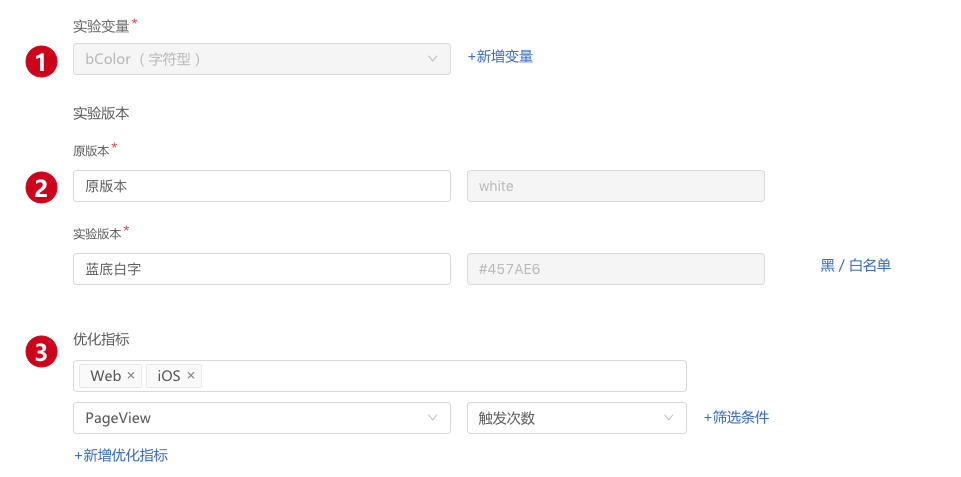
- 输入本次实验的实验变量,请跟负责开发的同事协商之后填入有实际意义的变量。例如案例中需要测试按钮颜色,所以设为bColor。
- 实验变量需要集成在应用中,所以变量名称只能含有英文字母,数字以及下划线,且下划线不能作为第一个字母;
- 实验中可以选择已经存在的实验变量,从而进行实验变量的复用。例如将文案内容作为应用的输入变量,如果可以通过后台控制该变量的输入,那么这个实验变量可以多次使用。为了实验的科学性,相同的实验变量只能在同一层实验中使用。
- 跟据实验方案创建实验版本,并且输入对应的变量值。
一般将未做任何更改的设计方案作为原始版本,这个版本将作为新方案的基准- 输入实验对应的实验名称,例如案例中将新的设计方案命名为蓝底白字;
- 输入实验变量对应的值,例如案例中将新的方案变量值定义为white;
- 输入该版本对应的黑白名单
注意如果用户同时作为黑白名单,黑名单优先- 当进入黑名单时,指定用户将不会进入该版本;
- 当进入白名单时,指定用户将会看到这个版本;
- 确定希望优化的数据指标,请提前沟通好希望优化的数据指标。优化指标仍然使用HubbleData的事件模型,选择对应事件的聚合度量。例如提交订单的用户数,以及转化率。
- 选择优化指标的事件
- 暂时仅支持HubbleData中已经上线或者提前定义好的的埋点事件;
- 如果产品还没有上线,但是仍然希望将这个事件作为优化指标。你可以在行为分析的埋点管理功能预先声明事件,我们会在后续的计算中自动做事件的匹配。
- 选择事件所在的应用终端,HubbleData效果评估模块支持跨应用进行分析。典型场景如不同版本在后端控制,但是埋点处于客户端。此时你需要在在优化指标应用选择处,选择多个客户端应用。
- 选择这个事件的聚合度量,HubbleData暂时仅支持以下三种度量:
- 事件的触发次数,例如案例中的点击单图的触发次数。选择点击单图的触发次数时,HubbleData将会自动计算点击单图的触发次数,点击单图的人均触发次数,点击单图的人均触发次数变化率;
- 事件的触发用户数,例如案例中的点击单图的触发用户数。选择点击单图的触发用户数,HubbleData将会自动计算点击单图的触发用户数,点击单图的转化率,点击单图的转化率的变化率;
- 事件的数值型属性的总值,例如支付订单事件有个金额属性是数值型,那么优化指标可以选择支付订单的金额总值。HubbleData将会自动计算总值,人均值以及人均值的变化率。
- 优化指标特别说明:
1. 人均触发次数=该事件的触发次数/该事件的触发用户数,分母并非实验参与人数 2. 转化率=该事件的的触发用户数/参与实验的触发用户数 2. 人均值=数值型指标的加总/事件的触发用数,分母并非实验参与人数
- 选择优化指标的事件
1. 实际操作中建议仅设定一个优化指标作为优化指标,以免指标过多干扰结果的评估。
2. 优化指标支持筛选条件,但是请谨慎使用,筛选条件的不当使用有可能会跟实验流量冲突。例如Web端实验中,如果筛选条件限定为macos,实验流量中必然有一部分windows用户无法触发这个事件,这时候人均优化指标的计算会偏小。