1. 数据解读
Hubble的计算指标分为活跃性的人均次数指标,提高转化的转化率值指标,效果类的总值型指标。本节将会以效果类的总值型指标作为主要依据,来对实验数据进行解读。
1.1. 关于A/B测试你需要知道的几个概念:
- 关于A/B测试的科学性
- A/B测试本质上是小流量测试,最早应用于药品的测试。自从2000年谷歌工程师开始运用到互联网行业,AB测试已经成为最流行的增长利器。
- A/B测试数据的效果评估依赖于统计上的假设检验、显著性评估以及参数估计。
- A/B测试的数据有效评估建立在抽样的合理性之上:
- 不同实验版本的用户特征应该基本保证一致,否则很难对两组的数据进行对比。
- 应该尽量回避特殊日期,例如双十一,这些特殊日期的用户行为一般跟日常行为有较大差距。
- 整个实验周期应该尽量覆盖工作日跟周末,可以保证整体实验结果在所有的日期内都是可信的。
- 关于A/B测试的显著性
- 由于各个版本的的流量是由产品来决定的,总量数据比较没有特别大的意义,Hubble主要对数据的人均值进行比较;
- 实验评估最终判断依据是实验版本的人均指标相对于原版本的是否有所提高,反映到数据上需要观察转化率的变化是否大于零。
- A/B测试本质上是小流量实验,为了保证数据评估的科学性,Hubble会计算样本的置信区间,用来计算数据的误差范围。版本效果的评估不仅需要变化率大于零,需要对置信区间进行分析:
- 当置信区间的下边界大于零时,非常大的概率(95%)版本是有提升的;
- 当置信区间的上边界小于零时,非常大的概率(95%)版本是由负效果的。
实际运行中如果选择多个优化指标,指标之间可能会产生冲突,推荐选择一个指标作为主要关注指标。
1.2. 真实数据场景
本案例将会以汇总数据作为主要参考数据,来对实验效果的评估进行解读。本例中以选择的指标的为点击菜单的触发次数,共会计算三个指标:
- 点击菜单触发次数:因为某一个数据的总值跟流量大小有关,所以一般来说总值对实验效果的评估意义不大。
- 点击菜单的人均次数:人均值在总值的基础上考虑了流量的因素,所以人均值是我们判断实验效果的主要依据。需要说明的是,转化率,人均金额跟此原理比较相似。
- 点击菜单的人均次数变化率:变化率在人均值基础上计算版本之间变化率,直观体现了实验版本与对照版本之间的数据差异。
- 置信区间:A/B测试本质上属于小流量抽样,置信区间的计算可以在统计上告诉我们数据是否可靠。需要说明的是HubbleData仅针对变化率指标计算了置信区间,为了实验是真实有效的,置信区间有以下三种情况,置信区间的具体说明请参考统计知识章节。:
- 对于希望提升的指标需要保证置信区间的下边界大于零;
- 对于希望降低的指标需要保证置信区间的上边界小于零;
- 置信区间穿过零时,数据指标在统计上是不显著的。
1.2.1. 数据场景1:
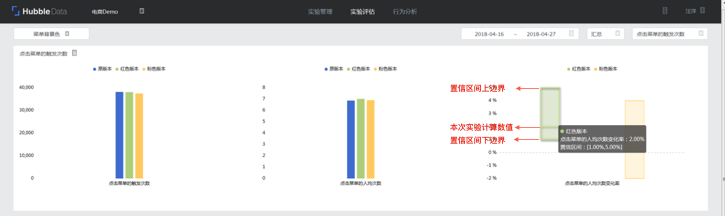
- 本次实验中,红色版本置信区间的下边界大于零。数据代表的含义为95%的情况下,红色版本的人均点击次数高于原版本的。本次试验中红色版本实际提升为2%。
- 本次实验中,粉色版本的置信区间穿过零。数据代表的含义为95%的情况下,粉色版本的人均点击次数相对版本高[-5%,15]。这种情况可以认为如下两种情况:
- 抽样数据不足,整体数据波动比较大,统计学上不显著。
- 粉色实验版本确实对数据没有实际的影响,可以认为更改对用户没有影响。
- 本次实验可以得出红色版本提高了点击菜单的使用次数。如果本次实验中希望让用户更多点击这个菜单,红色版本确实可以提高这个菜单的使用率。
1.2.2. 数据场景2:
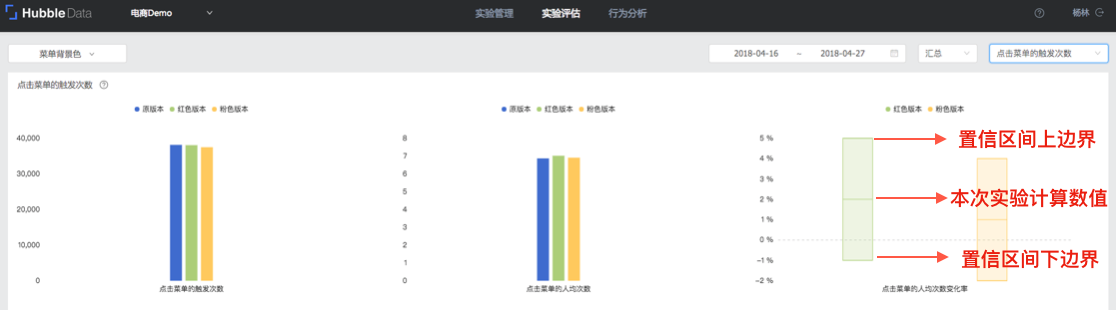
- 本次实验中两个实验版本在统计上都无法说明有明显提升或者降低。
1.2.3. 数据场景3:
- 本次试验中,红色版本置信区间的上边界小于零。数据代表的含义为95%的情况下,红色版本的人均点击次数小于原版本。本次红色版本的实际提升为-2%。
- 本次实验中,粉色版本的置信区间穿过零。数据代表的含义为95%的情况下,粉色版本的人均点击次数相对版本高[-5%,15]。这种情况可以认为如下两种情况:
- 抽样数据不足,整体数据波动比较大,统计学上不显著。
- 粉色实验版本确实对数据没有实际的影响,可以认为更改对用户没有影响。
- 本次实验中可以得出红色版本确实降低了菜单的使用次数。如果本次实验中希望让用户更多使用这个菜单,红色版本是对实验效果有反作用的。
1.3. 常见问题:
如果测试结果跟我的预期不一致,我该怎么办?
遇到这种情况,推荐按照以下顺序对实验进行检查:
- 实验进程中是否有什么特殊事件或者其他因素会影响用户使用,例如比较大的市场活动;
- 是否实验样本过小,实验数据不具有可信性;
- 你可以做A/A测试,来测试A/B测试工具的流量分配是否合理
产品测试是用某一个安卓渠道做的A/B测试,这种方式是否可行?
这种方式是不可行的。原因有两个方面:
- 每一个渠道的用户特性是不同的,渠道性质对数据影响很大。以渠道作为抽样,数据结论一般不具有普适性。
- 一般用渠道作测试,操作方式是在同一渠道上对新老版本进行对比。因为两份抽样的数据是在不同的时间区间,所以除了实验版本不同外,时间也不同。
实验预期出来是负的,这种实验有否有效?
也是有效的,如果实验数据是负的,后续产品设计中应该尽量回避这些问题。