1. 实验分层
本节将对HubbleData的实验分层功能进行介绍。
1.1. 流量分配
- A/B测试脱胎于药品测试的双盲实验,本身有非常严谨的科学依据。自从谷歌在互联网行业引入A/B测试以来,A/B测试已经成为互联网行业提升效率、优化运营的必备利器。随着A/B测试的普及,如何在科学性的前提下,尽可能降低成本成为我们研究的方向。
- A/B测试最基本的原则是样本除了测试变量之外,其他特征必须完全一致,即所有用户仅受单一变量的影响。基于这一原则,不同实验之间的用户不能重复。
暂时不考虑多变量实验解释如下: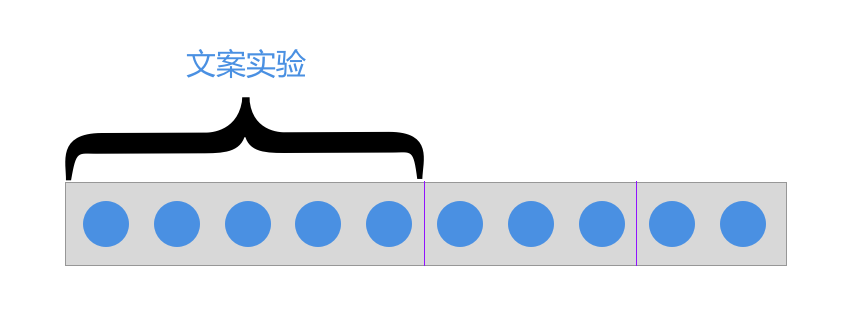
假设用50%的实验流量对注册文案进行实验。按照如上科学性要求,为了表面实验之间互相干扰,其他实验仅可以在剩余50%的用户中进行实验。反之,如果部分用户同时受文案跟颜色影响,我们很难对最后的结果进行分析。如此推衍,随着业务的发展以及实验的增多,后续实验必然面临流量不足的情况。不过现实世界中,情况往往是复杂以及难以预料的,粗暴的流量隔离将会限制我们对A/B测试大规模使用:
- 我们需要测试的模块跟其他产品的并没有直接关联,我们认为此种场景下,其他模块的实验对我们几乎没有影响;
- 我们需要使用100%的流量进行测试,我们认为此种情况下,虽然其他实验会影响我们,但是这块优先级确实比较高。
针对以上两种场景,实验本身跟已有实验没有关联,或者希望本次式样能够使用大部分流量。HubbleData引入分层机制来解决以上问题,接下来我们对分层进行介绍。
1.2. 分层简介
上一节对实验分层的背景以及面对的问题进行了说明,本节将对实验分层的概念、逻辑以及使用进行介绍。
HubbleData的分层机制
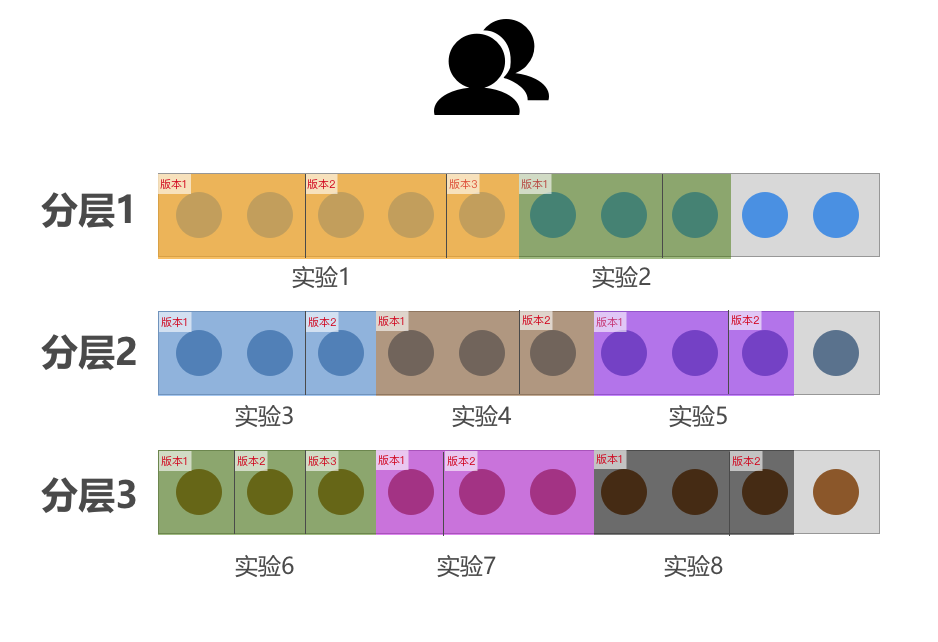
整体机制如下:
- 首先在第一个分层里面进行计算,以确定用户进入哪一个实验中;(假设为参与实验1)
- 接着,在第二个分层中进行计算,以确定用户进入哪一个实验中;(假设参与实验4)
- 最后,在第三个分层中进行计算,以确定用户进入哪一个实验中。(假设参与实验8)
流程上虽然描述为三步,实际运行中会同时完成上述三个流程。上述案例中,用户同时参与不同分层中的实验1,实验4与实验8。体现在HubbleData的产品设计上,如果某一个分层已有70%的流量被分配,新创建的实验最多使用30%的流量。
分层在产品中的使用
回到我们第一个小节中提出的问题,如何在科学性的前提下降低实验成本,最优化利用实验流量。
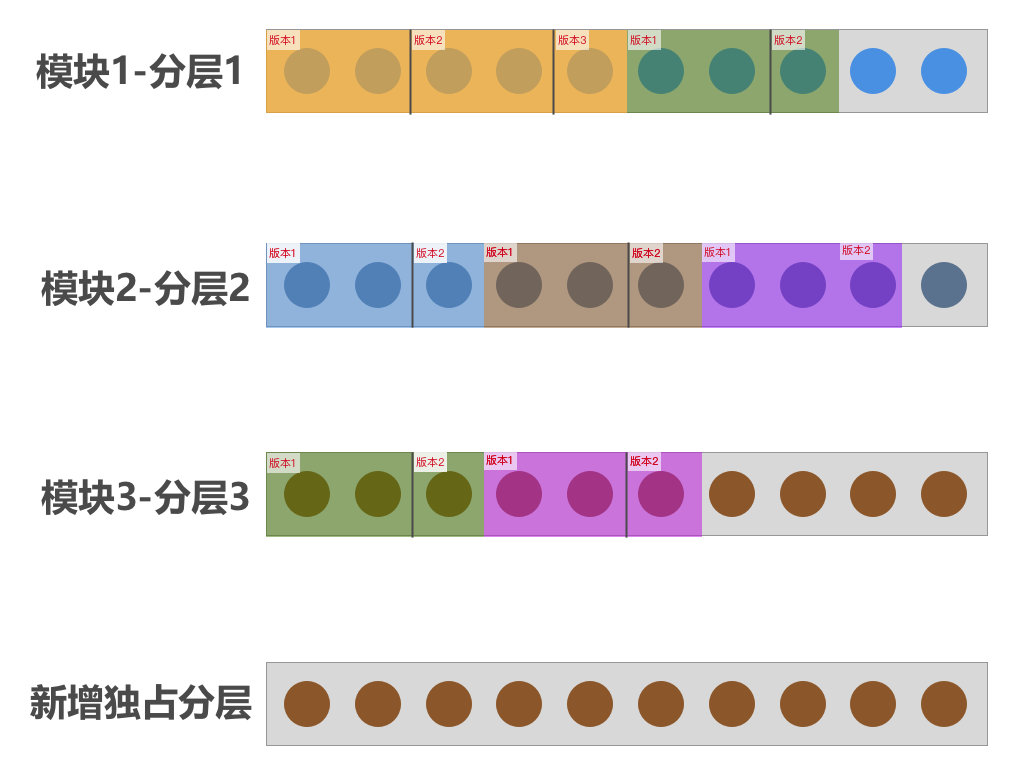
分层使用的场景以及解决的主要问题:
- 如果不同实验互相影响,并且想对某一个关键因素进行测试。我们可以选择将不同实验添加到同一分层,此时用户仅会进入其中一个实验中。
- 如果不同实验没有关联,或者关联非常小,典型如产品的会员模块跟注册模块。我们可以在不同模块使用不同分层,此时可以保证不同模块的实验流量充足。
- 如果产品改版比较大,希望全流量测试或者大流量测试。我们可以选择新增分层,此时实验可以使用100%的实验流量。
最后,我们对分层背后原理或者机制进行讨论。
抽象来看,同一个用户每经过一次分层都会被重新分配一次。其实,我们完全可以认为用户在这三个分层中是三个用户,也就是用户被复制了三份。抽象来看分层对应两层意思:
- 抽象来看,通过分层设计,我们将每一个用户复制成多份;
- 物理层面,这些分层对应同一个用户实体,只是处于不同的时间段。
1.3. 其他问题
- 每一个分层的实验流量都是有限的,这种情况意味着:
- 新增实验只能使用指定分层的剩余流量,并不能使用全部流量;
- 如果某一个版本最终结果胜出,此时通过HubbleData的运行控制模块,不一定能将流量调整到100%实现上线(需要确保此时没有其他实验在运行,如果此时某一个实验占有30%流量,该版本最大流量只能调整到70%)
- 理想状态下不同模块使用不同分层,可以达到流量的最大化运用。实际使用请不要误用分层:
- 实验流程上,需要保证用户体验不受影响。如果实验处于不同分层,此时实验流程互相冲突将会造成用户困扰,影响用户体验。例如:注册环节中不同用户对应会员模块不同的会员权益。
- 实验过程中,需要保证不同分层的实验方案不会影响到同一实验指标。以提交注册为例,不宜将注册环节的不同步骤放在实验的不同分层中。